|
Lee Roy Beach: Blog, Art, and Publications about The Psychology of Narrative Thought |
|
|
The Psychology of Narrative Thought
Book:
The monograph previously posted here is no longer available because a highly revised and expanded version has been published: The Psychology of Narrative Thought: How the Stories We Tell Ourselves Shape Our Lives. I selected an on-demand publisher to keep the price low: hardback ($29.99), paperback ($19.99), and e-book ($9.99). It can be ordered through www.amazon.com, www.barnesandnoble.com, www.xlibris.com or your local bookstore. You can learn more at www.thepsychologyofnarrativethought.com
The Contents:
Chapter 1: The Puzzle: Historical overview of the problem of conscious experience and the various solutions that have been proposed, the latest of which is the subject of this book, the Theory of Narrative Thought.
Chapter 2: Narratives: The nature and properties of narrative thought and how it gives unity and direction to experience by uniting the past and present to forecast the future. Chapter 3: Forecasts: The nature and properties of forecasts and appraisal of the desirability of the future they predict. Chapter 4: Memory: The role of memory and cognitive rules in the construction of both narratives and forecasts. Chapter 5: Values: The role of primary and secondary values in determining the desirability of forecasted futures. Chapter 6: Plans: The nature of action sequences designed to intervene in the course of unfolding events in an effort to ensure that the future, when it arrives, is more desirable than that which has been forecasted. Chapter 7: Decisions: The mechanism for determining the desirability of the forecasted future, what to do if it is undesirable, and whether efforts to change it are succeeding. Chapter 8: Paradigms: The nature of explanatory and procedural narratives that are designed to provide information to, and overcome the limits of, everyday narrative thought. Chapter 9: A Decision Paradigm: The logic of the procedural narrative that helps us decide about the desirability of forecasted futures and the adequacy of plans to remedy things when they are undesirable. Chapter 10: Expanding the Paradigm: The logic and procedures for a decision paradigm for complex, life changing decisions. Chapter 11: The Paradigm for Organizations: An example of how the expanded decision paradigm is used for organizational decisions. Chapter 12: Antecedents of the Theory: Discussion of other theories that have informed and shaped the theory of narrative thought. Chapter 13: Research: A discussion of the research needed for the theory and suggestions about how it should be done. Summary: Brief overview of the theory. Sources and Further Reading: References for both cited work and other, related, publications.
Manuscripts:
Cognitive Errors and the Narrative Nature of Epistemic Thought In Brun, W., Keren, G., Kirkebøen, G., & Montgomery, H. (2011). Beginning with work on unaided human judgment and decision making and continuing in other areas, primarily behavioral economics, researchers have demonstrated an impressive array of “cognitive errors.” These are discrepancies between the behavior of the participants in the experiments and the behavior implied or prescribed by various formal paradigms for solving specific classes of problems or making specific classes of inferences—probability theory, rational choice theory, formal logic, various aspects of economic theory, and the like. When this research was first undertaken, the agenda was to use these discrepancies to generate a general descriptive theory of judgment and decision making. As it turned out, Prospect Theory (Kahneman & Tversky, 1979) was the only thorough-going attempt to follow through on this agenda. Instead, a disparate set of concepts has come to be used to both label and “explain” a multitude of cognitive errors that have been observed in a multiplicity of tasks. This has resulted in a very large literature; at last count, Wikipedia listed 93 cognitive errors. But, the original goal of a general descriptive theory seems to have been abandoned. This is not to say that the work on cognitive errors lacks a theoretical underpinning. Indeed, the use of formal paradigms as criteria for correctness implicitly assumes that they are prototypes for correct thinking. This assumption has roots in the psychological theories of Egon Brunswik (1947), Jean Piaget (1952) and others whose views were influential at the time that the cognitive error research was getting underway. These theorists viewed people as “intuitive scientists” who learn about the physical world as a result of having to cope with its demands and constraints. From this it followed that because the physical world is described by the physical sciences, discrepancies between performance and the prescriptions of scientific paradigms can be used to evaluate how learning progresses; hence the focus on errors. That this viewpoint shaped the early work in judgment and decision making, is clear in Peterson and Beach’s (1967) early article, “Man as an Intuitive Statistician” (the title of which, in fact, quoted Brunswik). The article used the table of contents of a typical statistical textbook to organize a review of the existing research on unaided human judgments about probabilistic events; explicitly citing statistical theory as the prototype for thinking about such events. Although the article’s conclusion contained all the usual nuances and hedges, many critics interpreted it as an overgenerous endorsement of statistical theory as a descriptive theory of people’s judgments. Their skepticism prompted a torrent of research. But, for all its success at refuting the descriptive adequacy of statistical theory, this research produced little more than a list of loosely related errors, with nothing to take statistical theory’s unifying role. Sometime near the zenith of cognitive error research, an old idea (see Hacking, 1975, for the history) was given new life by Kahneman, Slovic, and Tversky (1982; Tversky and Kahneman, 1983). They suggested that cognitive errors reflected a conflict between two different modes of thinking, modes that became known as aleatory and epistemic. Aleatory thinking is the logic of gambling and probability theory (an aleator is a dice player). A major feature of aleatory logic is that all events in a particular set are mutually intersubstitutable so that statements about the characteristics of any event are based on its class membership rather than on its unique properties. In contrast, epistemic thinking involves the unique properties of events as well as information about the conceptual systems in which they and their properties are embedded. Barnes (1984) investigated this aleatory/epistemic distinction and obtained results suggesting that both modes of thinking generate judgments and predictions, but that they may do so in different ways that frequently yield different results. She concluded that when an experimenter adapts aleatory logic as the standard of correctness, but the participants in the experiment think epistemically, one should expect differences and that it may not be sufficient to merely call the differences cognitive errors. Attributing cognitive errors to the difference between aleatory and epistemic thinking was provocative but ultimately not very productive. Although aleatory thinking was clearly defined by probability theory, epistemic thinking tended to be defined as anything that was not clearly aleatory. Moreover, it seemed rather extreme to condemn cognition in general on the basis of errors in judgments that were largely about probabilities. In an attempt to provide a more useful, yet broad, characterization of epistemic thought, Beach and Mitchell (1990; Beach, 1990) proposed a new theory, called Image Theory. The theory was successful in that it generated a good deal of research but its central concept, images, turned out to be opaque. An effort to replace images with something that retains their essence but is more easily understood ended up requiring revision of other of the theory’s elements. The revision resulted in a view of epistemic thought (Beach, 2010) that adopts and significantly extends Walter Fisher’s (1989) ideas about the role of narratives in communications, rhetoric, and criticism. In the revision, called the Theory of Narrative Thought (Beach, 2010), images are replaced by narratives and the other elements are revised or replaced by concepts borrowed from other theorists who have sought to cast judgment and decision making in other than aleatory terms, especially Gary Klein’s (1989) Recognition Theory of decision making. In addition, by elaborating upon Bruner’s (1986) differentiation between paradigms and narratives, the Theory of Narrative Thought encompasses both aleatory and epistemic thinking within a single over-arching framework. The Theory of Narrative Thought The Theory of Narrative Thought begins with the assumption that everyday thought is in the form of narratives, which are causally motivated, time-oriented chronicles, or stories, that connect the past and present with the future, thereby giving continuity and meaning to ongoing experience. Narratives are not simply the voice in your head, nor are they simply words, like a novel or a newspaper article. They are a rich mixture of memories and of current visual, auditory, and other aspects of awareness, all laced together by emotions to form a mixture that far surpasses mere words in their ability to capture context and meaning. The elements of narratives are symbols that stand for real or imagined events and actors, where the latter are animate beings or inanimate forces. The glue that binds the elements is causality and implied purpose. The narrative is a temporal arrangement of events that are purposefully caused by animate beings or are the result of inanimate forces. The narrative’s story line is the emergent meaning created by arranging the elements according to time, purpose, and causality. Just as arranging words into sentences creates emergent meaning that unarranged words do not have, and just as arranging sentences into larger units creates even more emergent meaning, arranging events, actors, time, purpose, and causality into a narrative creates the emergent meaning that is its story line or plot.A “good narrative” is coherent and plausible; coherent when effects can be accounted for by causes and plausible when the actions of its actors are consistent with their own or similar actors’ actions across contexts (i.e., across different narratives). We tend to believe that good narratives are valid. We each have many narratives in play at any time, one for each area of our lives, and we switch back and forth as required by the context. The narrative that is the focus of attention at the moment is called the current narrative, the story that is being constructed to make sense of what just happened, what is happening right now, and what will happen next. That is, it is partially memory, partly current awareness, and partly expectations for the future. As each second passes, as the present becomes the past, that part of your current narrative that was the present a moment ago becomes the past and is stored in episodic memory. Consider an analogy: The “crawl” is the writing that appears at the bottom of the picture when you watch the evening news. It appears on one side of the screen, moves across, and disappears on the other side. Think of the past as the information that has disappeared, the information on the screen as current experience, and the information that has yet to appear as the future that will unfold in due course. As you read, you store the information that is disappearing, you read what is currently visible, and you anticipate what has not yet appeared. The latter is important because you really do not know what will appear, but based on what you have seen and what you are seeing, you can make a fairly good guess about the future. This “good guess” about the future is called the extrapolated forecast, because it is an extrapolation of the past through the present and into the future. The extrapolated forecast is what you expect to happen if you (or someone else, or something else) do not intervene to change the course of events. This extrapolated forecast seldom is very detailed, but its overall desirability is evaluated by weighing its prominent features against the corresponding features of your desired future. The desired future is dictated by your enduring values and your more transient preferences (see Beach, 2010 for details). If the forecasted future is not too deviant from your desired future, you can simply continue doing what you are doing and let the future unfold as it will. If it is too deviant from your desired future, you must intervene to guide the course of unfolding events toward a more desirable future. Decision making occurs when the forecasted future is compared to the desired future and either accepted or rejected. This part of the theory is called narrative-based decision making (N-BDM) and constitutes a significant part of the theory. Intervention requires you to have some notion of what you are going to do. This is accomplished by devising a plan, however rough, and forecasting the results of its implementation. The forecast is called the action forecast because it is what you think will happen if you do what you propose to do. As with the extrapolated forecast, the action forecast is compared to your desired future. If its expected results are not too deviant from the results you want, it is implemented—with continual monitoring to see that it is working to produce the future you desire. If it is not working properly, the plan is repaired or it is rejected and another is formulated. An action forecast for the repaired or new plan is then compared to the desirable future, and so on until an acceptable plan is obtained, whereupon its implementation begins.The theory is not as simplistic as this description makes it sound, but this is the essential idea. The fuller version (Beach, 2010) closely examines the nature of narratives and forecasts, explores the role of memory and values in the process, and outlines the structure and use of plans—from simple habits to elaborate schemes for achieving desirable ends. Paradigms Narrative thinking, and the actions it prompts, is generally sufficient for everyday life. But narratives, which are great for the “big picture,” do not do well when precision, detail, or complexity is required. And, just as we humans have invented tools to extend and improve our physical abilities (levers, pulleys, pencils, hammers, telescopes, computers and other things that help us do tasks that we otherwise could not do easily), so too have we invented tools, called paradigms, that have the rigor, precision, and ability to deal with complexity that narratives do not have. The function of paradigms is to acquire information that we need to improve the plausibility and coherence of our narratives. Actually, Narrative Thought theory views paradigms as a special case of narratives in general. As a result, it is convenient to differentiate between the story-like narratives discussed above, called chronicular narratives, and tool-like narratives, called paradigmatic narratives. Moreover, because paradigmatic narratives have two functions, we differentiate between explanatory paradigms and procedural paradigms. Explanatory paradigms tell us how events (happenings, persons, objects, or concepts) relate to each other and, therefore, what to expect of them. For narrative thought, linking an event to other events within a conceptual framework, the paradigm, explains the event. Examples of explanatory paradigms are taxonomies for classifying plants, animals, minerals, and societies as well as conceptual frameworks such as scientific theories, political ideologies, religions, and systems of rules such as bodies of law or codes of professional conduct. Each paradigm allows for both categorization of the event in question and access to information about the nature of events in the category, and by inference about the specific event in question.Procedural paradigms are sets of steps for manipulating both cognitive and physical events in order to achieve desired ends. Examples are recipes for cooking salmon or mixing a cocktail, instructions for assembling a set of bookshelves or operating a drill press, manipulative algorithms such as in arithmetic, algebra, geometry and other forms of mathematics. The result of applying a procedural paradigm, either success or failure, provides information for refining the chronicular narrative that prompted the paradigm’s use in the first place. The Structure of Chronicular and Paradigmatic Narratives Chronicular narratives are particularistic and are structured around time. The current narrative, the extrapolated forecast, and the action forecast are all chronicular narratives and all consist of events arrayed along a time line. Purpose and causality give meaning to the specific events and their ordering, but the underlying structure is the time line.Explanatory paradigmatic narratives are general and structured by subordination, by how categories of elements relate to one another in a hierarchical or quisihierarchical manner. Textbooks, for example, are explanatory paradigms and their subordinative structure is revealed by their hierarchy of topic headings—where the topics are categories. Meaning is provided by a concept’s location in this hierarchical structure and its links to other concepts in the hierarchy. Procedural paradigmatic narratives also are general but they are structured by conditional sequentially. Instructions, for example, are procedural paradigms consisting of sequences of steps; execution of each step is conditional upon the results of the step(s) that preceded it. Their generality comes from the applicability of the instructions to any task in the category for which this paradigm was developed. Origins of Paradigms Paradigmatic narratives derive from individuals’ efforts to construct plausible, coherent chronicular narratives. To the degree that an ad hoc paradigm achieves this, it is deemed to be valuable and is stored away in the person’s memory for possible future use; this is called a private paradigm. Success often leads to the paradigm being recommended to others, whereupon it becomes a public narrative. Public explanatory paradigms are given labels like world history, the periodic table, the theory of the firm, astronomy, political science and so on. Public procedural paradigms are given labels like probability, geometry, long division, How to start a car, How to iron a shirt, and the like.Once they become public, paradigmatic narratives are available for others to revise and develop. Particularly in the hands of scholars, this often leads to explanatory and procedural paradigms that have a subtlety and sophistication that far outpaces the understanding or day-to-day needs of the majority of people. Probability is a good example. Starting with an everyday chronicular need to express more precisely one’s uncertainty about events (“It probably will rain,” “He probably is a thief”), probability theory has become a self-contained mathematical theory in which the concept of probability has become so esoteric that it is virtually unrecognizable as the subjective uncertainty that started it all. This lack of resemblance between elaborated public paradigms and their less sophisticated private forbearers means that they are fairly far removed from the everyday thought processes that originally gave rise to them. This is the point, of course; paradigms are tools for obtaining needed information through use of precise, objective, structured systems that are beyond the scope of everyday chronicular narrative thought. It is not surprising that people’s everyday thinking fails to conform to the dictates of public paradigms. Paradigms only exist because we cannot normally think that way. If we could, there would have been no need to develop the paradigms in the first place.Indeed, the wonder is not that we do not think paradigmatically. It is that, collectively, we have recognized the limitations of our chronicular narrative thought and, over the years, have invented paradigms to help us overcome those limits. In reference to our earlier discussion of cognitive errors; berating ourselves for not thinking paradigmatically is as pointless as berating ourselves for not running as fast as a locomotive or flying like an airplane or calculating as accurately as a calculator, tools which exist precisely because we cannot normally do what they allow us to do. In this light, cognitive errors serve less as indictments of human thinking and more as sign posts that mark the boundaries of our thinking. A New Mission for Cognitive Error Research None of this is to say that research on cognitive errors is unimportant; quite the opposite. Although humans, collectively, have recognized that there are limits to chronicular narratives and that there is a consequent need for paradigmatic narratives, the research shows that, individually, we routinely fail to recognize our own limits—so the need for paradigms often goes unappreciated, even when we know about them. As has been stated so many times, research on cognitive errors is important because the errors can be dangerous. However, merely demonstrating more and more errors does little to mitigate these dangers.Cognitive error research needs to adopt a new mission. It needs to build upon its collection of demonstrations, each of which explores a small outpost at or beyond the boundary of useful chronicular narrative thought, by undertaking parametric studies that systematically map that boundary and then study how the boundary is, in effect, expanded by the use of paradigms. The existing list of tenuously related errors only provides glimpses of this boundary. Unless we go beyond our list, we will never fully understand epistemic thought nor develop a technology for improving it Toward an Understanding of Epistemic Thought What might the effort to understand epistemic thought look like? It seems to me that it would be tripartite. The first part would be a theory of epistemic thought. The second part would be a theory of contexts and their demands; that is, a theory of tasks. The third part would be a theory of paradigms.Of course, I nominate chronicular narrative thought as the theory of epistemic thought, the first part of the tripartite theory. The second part, a theory of tasks, should view tasks separately from what it takes to successfully undertake them, in the sense that medicine distinguishes between disease as a malfunction of a bodily systems that can be studied in and of itself and treatment protocols which are paradigms for treating the disease once it is manifest in a patient. In our case, the theory of tasks begins with a taxonomy of the malfunctions that are common to categories of contexts or systems, where both words are used in the broadest sense. These malfunctions set the parameters of tasks, so a central feature of the taxonomy would be complexity (multiplicity of factors that define the malfunction) and time available for correcting the malfunction. The theory of tasks would be the totality of the taxonomy and the rules for locating a malfunction/task within it.The third part of the tripartite theory would be a theory of paradigms, for which I nominate paradigmatic narratives. This would consist of a taxonomy of explanatory and procedural paradigms together with the rules for locating a paradigm within the taxonomy. The paradigms in this taxonomy are the multitude of formal prescriptions for identifying and correcting the multitude of malfunctions to which systems are subject.Research would begin by mapping the paradigm taxonomy onto the taxonomy of system malfunctions, much as diagnostic and treatment protocols are mapped onto diseases. This would be followed by parametric studies of unaided humans of various degrees of training and motivation. Tasks of increasing complexity within a category would be presented, crossed with increasing time constraints, and participants would be asked to perform them. The points at which performance fails would allow us to trace the boundary of useful epistemic (chronicular narrative) thought—indicating where the use of paradigms (paradigmatic narratives) should begin. Doing this with different groups of participants would allow us to see how the boundaries are extended by training, motivation, and the availability of appropriate paradigms—not substantially different from seeing how the boundaries of a person’s ability to dig a hole is extended by training, motivation, and the availability of a shovel Summary The theory of Narrative-Based Decision Making grew out of an effort to refine the concept of epistemic thought. Although richer than can be presented in the space available here, the theory is basically simple. The key concept is the cognitive narrative, the story that makes sense of our past and present experience and that allows us to make educated guesses (forecasts) about the future. Decisions arise when the forecasted future violates our values and preferences, causing us to intervene in the ongoing flow of events to create a more acceptable future.Narratives are temporal arrangement of events that are purposefully caused by animate beings or inanimate forces. There are two kinds of narratives, chronicular and paradigmatic. Chronicular narratives need not be true (they can be imaginary or conjectural) but we attempt to make our current narrative about what is happening right now as valid as possible because it is the basis of forecasts and consequent actions—where plausibility and coherence are surrogates for validity.Paradigmatic narratives grow out of our need to think about things that are not easily handled by chronicular narratives. They are tools for expanding our narrative ability by providing information to use in the construction or refinement of other narratives. Cognitive errors are examples of what happens when we try to use chronicular narrative thought to deal with tasks for which paradigms are better suited. As such, they suggest a new mission for researchers—the parametric examination of the boundaries of useful chronicular narrative thinking and how these boundaries are extended by the use of paradigms. In short, the idea of humans as proto-scientists emerges anew. Just as scientists transcend the limitations of their narratives about the natural world through the use of scientific paradigms, so too can ordinary people learn to use paradigms to improve and expand their narratives about their own worlds. Doing so can provide them a deeper and more justifiable understanding of their ongoing experience as well as mitigating the errors that could endanger their efforts to manage the ongoing course of their lives. References Barnes, V. E. (1984). The quality of human judgment: An alternative perspective. Unpublished doctoral dissertation, University of Washington, Seattle.Beach, L. R. (1990). Image theory: Decision making in personal and organizational contexts. Chichester, UK: Wiley. Beach, L. R. (2010). The psychology of narrative thought: How the stories we tell ourselves shape our lives. Bloomington, IN: Xlibris. Beach, L. R., & Mitchell, T. R. (1990). Image theory: A behavioral theory of decisions in organizations. In B. M. Staw and L. L. Commings (eds.), Research in Organizational Behavior (Vol. 12). Greenwich, CT: JAI Press. Brunswik, E. (1947). Systematic and representative design of psychological experiments, with results in physical and social perception. Berkeley, CA: University of California Press. Fisher, W. R. (1989). Human communication as narration: Toward a philosophy of reason, value, and action. Columbia, SC: University of South Carolina Press.Hacking, I. (1975). The emergence of probability. New York: Cambridge University Press. Kahneman, D. & Tversky, A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47, 263-291. Kahneman, D., Slovic, P., & Tversky, A. (1982). Judgment under uncertainty: Heuristics and biases. New York: Cambridge University Press.Klein, G. (1989). Recognition-primed decisions. Advances in Man-Machine Systems Research, 5, 697-720. Peterson, C. R., & Beach, L. R. (1967). Man as an intuitive statistician. Psychological Bulletin, 68, 29-46.Piaget, J. (1965). The moral judgment of the child. New York: Free Press Tversky, A., & Kahneman, D. (1983). Extensional versus intuitive reasoning: The conjunction fallacy in probability judgment. Psychological Review, 90, 293-315.
When a Difference Makes a Difference in theScreening of Decision Options.
Lehman Benson III, Daniel P. Mertens, and Lee Roy Beach
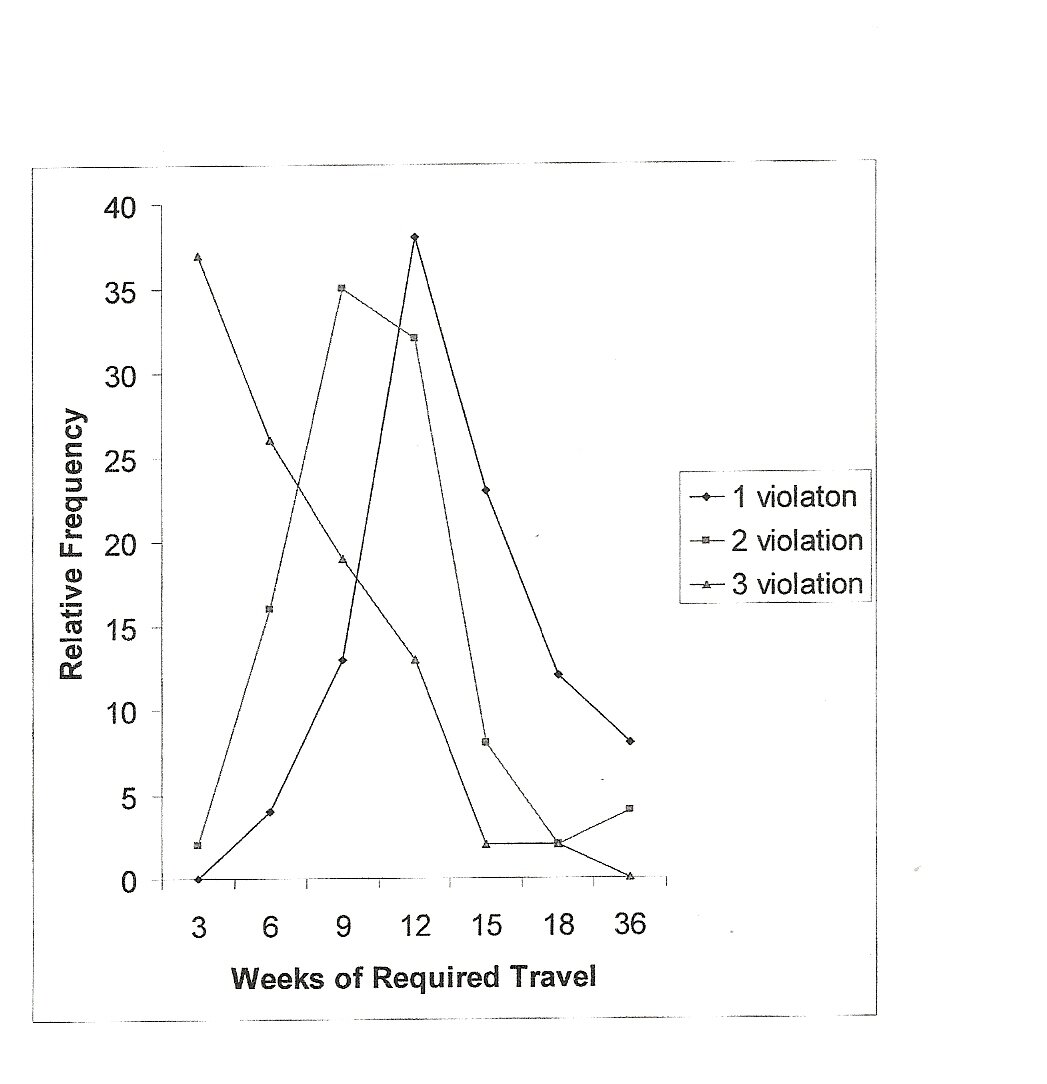
Abstract Abstract In previous research (summarized in Beach 1993,1998; Beach & Connolly, 2005) we have examined how differences, called violations, between decision criteria, called standards, and the features of available options lead decision makers to drop some options and retain others for subsequent choice of the best from among them, a process known as pre-choice screening. In all of this work, options' features either clearly violated the standards or they clearly did not and the number of violations was varied. Depending upon the circumstances, it is found that three or four violations, called the rejection threshold, is generally sufficient to screen an option out of the choice set. This has been called the rejection threshold (Beach & Mitchell, 1987, 1990). The present research addresses the question of what constitutes a violation. That is, how big the difference must be between a decision standard and the corresponding feature of an option before it counts as a violation and therefore weighs against retention of the option for the choice set. In short, is there evidence of a violation threshold? Two areas of research are particularly relevant to degree of violation. In discussing lexicographic semiorders, Tversky (1969) proposed that choices between options may be made by comparing them on a single feature and if the difference between them exceeds some minimal value, called eta (e), the option with the more favorable value on the dimension should be retained and the other rejected. The concept of importance here is e, which is similar to a difference threshold in psychophysics; the point at which a difference between two stimuli can be detected. In both cases, e and difference thresholds, the notion is that small, sub-threshold differences make no difference but large, supra-threshold discrepancies do. Moreover, difference thresholds have been shown to vary according to the circumstances (e.g., Swets, 1964). The second area of relevant research concerns decision makers' judgments of equivalence (Beach, Beach, Carter & Barclay, 1974; Beach, 1990). Here it is found that a judgment (How tall am I?) or an answer to a problem to be solved in one's head (what is 86% of 2537?) can deviate from a standard, usually the correct value, to some degree and still be regarded by participants as essentially equivalent to the correct value, while larger deviations are regarded as wrong. As with difference thresholds, equivalence thresholds vary according to the circumstances, and there are individual differences. Returning to the question of degree of violation and the acceptance or rejection of decision options, difference thresholds, e, and equivalence thresholds all suggest that we should expect a difference between a decision standard and a corresponding feature of a decision option to be tolerated up to a point, a threshold, above which it will be regarded as a violation and, therefore, evidence that the option should be rejected, i.e., eliminated from further consideration. That is: A second hypothesis is suggested by introspection and observation: If you already know that an option has significant flaws (violations), an additional small flaw that otherwise would be insignificant may become significant, moving the decision option toward rejection. For example, suppose you are looking into the details of a house you are thinking of buying. As you discover some of the house's shortcomings, you become increasingly uneasy about whether you should buy it. The more shortcomings you uncover, the more apt you are to regard the next one, even a small one that otherwise would not trouble you, as telling evidence of the house's unsuitability. Thus: In other words, violation thresholds decrease as the number of known violations increase. Experiment 1 Hypothesis #2 was tested by varying the number of violated features the jobs had in addition to required travel. For one of the three jobs, all features except travel matched their corresponding standards; this will be called the 1 violation condition even though small amounts of required travel were not expected to count as a violation. A second of the three jobs had one clear violation in addition to travel; this will be called the 2 violation condition. The third of the three jobs had two clear violations in addition to travel; this will be called the 3 violation condition. The prediction was that the rejection threshold for required travel would decrease as the number of additional violations increased. Method Procedure: Participants were presented with four-page booklets the first page of which instructed them to: "Imagine that you are a 22 year old student who will soon graduate with a bachelor's degree in Marketing. You have gone to the Placement Center to look at available jobs. The Center has provided you with descriptions of three jobs in marketing, all of which pay the entry level salary. Each of the jobs is described in terms of 7 features: (1) firm size, (2) location, (3) creative freedom, (4) administrative responsibility, (4) whether there is an initial training period, (5) whether extensive travel is required, and (7) amount of annual vacation granted during the first two years with the firm." "You have strong requirements in regard to each of these 7 job features: You want to work for a small firm, preferably in Tucson. You want a high degree of creative freedom, but a low degree of administrative responsibility until you have been on the job for a few years. You want an initial training period so you can more easily fit into the firm, you want as little travel as possible, and you want at least 2 weeks of vacation. Of course, you may not get precisely what you want, but these requirements reflect your preferences." "In light of your requirements, please read each job description and answer the questions at the end of each description." Each of the next three pages of the booklet contained a description of one of three jobs; a list of 6 features of the job (excluding travel), each of which corresponded to one of the job seeker's requirements. The features were always listed in the same order for each job. Thus, each job was some combination of: Firm Size: Large/Small; Location: Tucson/Out of State; Creative Freedom: High/Low; Administrative Responsibility: High/Low; Initial Training: Yes/No; Required Travel: ?;Vacation: 1 week/2 weeks For the 1 violation job, travel as the only feature that was different from the standard. For the 2 violation job, low creative freedom in addition to travel violated their respective standards. For the 3 violation job, both low creative freedom and large firm size in addition to travel differed from their respective standards. Results See Fig. 1 at end of manuscript. Hypothesis #2 also was supported. As can be seen in Figure 1, the modal threshold for the 98 participants who had three distinct thresholds was lower when travel was accompanied by another violation than when it was the only violation, and the modal threshold was even lower when travel was accompanied by two other violations. The modal threshold (38% of the 98 participants) for the 1 violation condition (travel only) was 12 weeks of required travel, with 78% of the 98 participants having thresholds at 9, 12, or 15 weeks. The modal threshold (36%) for the 2 violation condition (travel plus low creative freedom) was 9 weeks of required travel, with 85% of the 98 participants having thresholds at 6, 9, or 12 weeks. The modal threshold (37%) for the 3 violation condition (travel plus low creative freedom plus large firm size) was 3 weeks of required travel, with 83% of the 98 participants having thresholds at 3, 6, or 9 weeks. Discussion Experiment 2 Method Procedure: Participants were presented with nine-page booklets, the first page of which contained instructions and the following eight pages of which contained lists that described each of eight jobs, one job to a page. One of the eight jobs had no violations, one had 1 violation, one had 2 violations, and so on up to a job for which all 7 features were violations. Seven of the eight jobs merely provided filler within which the eighth, the target job, was imbedded. The eight jobs were presented in random order in each booklet. The instructions were the same as in experiment 1 with the following exceptions: The results of Experiment 2 are shown in Table 1. In what follows, whenever a difference between proportions is termed "significant," it is the result of a standard normal variate test for proportions with p at .05. Table 1. The proportion of participants in each group who decided to apply for the target job at each level of required travel for each violation condition in Experiment 2. The horizontal bars indicate that all of the proportions on one side of the bar are significantly different from all the proportions on the other side and the proportions on one side of a bar are not significantly different from one another. Weeks of Required Travel3 6 9 12 15 18 … ……. 361 Violation 90 95 85 | 60 45 55 60 2 Violation 85 | 50 30 40 39 50 60 3 Violation 50 40 40 35 40 50 |10 Each cell in the table contains the proportion of the 16-18 participants in that group who decided to apply for the target job. The proportions in each row reflect the effects of increasing the amount of required travel holding the number of other violations constant. Looking at the row for 1 violation, where travel is the only discrepant feature, there are no significant differences among the proportions of decisions to apply for the target job for 3, 6 and 9 weeks of required travel nor among the proportions for 12, 15, 18 or 36 weeks. However, each of the 3-9 week proportions is significantly different from each of the 12-36 week proportions, indicating a significant drop in decisions to apply between 9 and 12 weeks. This implies that when decision makers know of no other violations for the job, the threshold at which a difference between required travel and the standard of "as little travel as possible" becomes a violation lies between 9 and 12 weeks of required travel. Recall that 12 weeks was the modal threshold in experiment 1. In the row for the 2 violation condition, the proportion of decisions to apply for a job requiring 3 weeks of required travel is significantly different from each of the proportions for 6-36 weeks of required travel, none of which are significantly different from each other. This implies that when decision makers know of one other violation for the job, the threshold at which a difference between required travel and the standard becomes a violation is between 3 and 6 weeks, which is lower than the modal threshold of 9 in experiment 1. In the row for the 3 violation condition, even 3 weeks of required travel is sufficient to make half the participants decide to reject the target job. None of the proportions in the row is significantly different from the others except for 36 weeks (.10), which is significantly lower than all other proportions in the row, as well as being significantly lower than the other proportions in the column, an anomaly that will be addressed below. Excepting the 36 week proportion for the moment, the results in this row of the table imply that when decision makers know of two other violations for the job, the threshold at which a difference between required travel and the standard becomes a violation is between 0 and 3 weeks. Recall that the modal threshold was 3 in experiment 1. Each column in the table reflects the effects of increasing the number of other violations, holding the weeks of required travel constant. Looking at the column for 3 weeks of required travel, the proportions for travel only (1 violation condition) and travel plus low creative freedom (2 violations) are not significantly different from one another, but they both are significantly different from the proportion for travel plus low creative freedom plus large firm size (3 violations). This implies that 3 weeks of required travel is not considered to be so different from the prescribed standard of "as little travel as possible" that it counts as a violation unless the job has at least two other violations. For both 6 and 9 weeks of required travel, the proportions for travel only (1 violation) are significantly different from the proportions for travel plus low creative freedom (2 violations) and from the proportions for travel plus low creative freedom plus large firm size (3 violations), but the latter proportions are not significantly different from each other. This implies that neither 6 weeks and 9 weeks of required travel are considered to be so different from the standard of "as little travel as possible" that they count as violations unless the job has at least one other violation. For 12 or more weeks of required travel, none of the proportions are significantly different from each other (except for 36 weeks for 3 violations). This implies that any amount of required travel equaling or exceeding 12 weeks is so different from "as little travel as possible" that it constitutes a violation, whether or not the job has other violations. Discussion The anomaly in Table 1 is the .10 for 36 weeks in the 3 violation condition. Although .60 of the participants decided to apply for the job when 36 weeks of travel was its only violation, and the same proportion decided to apply for it when it had both 36 weeks of required travel and low creative freedom as violations, adding yet another violation, large firm size, seems to have been the straw that broke the camel's back, almost nobody was interested in the job. The instructions about impending parenthood may have heightened participants' sensitivity both to the three violations and to the 36 weeks of required travel. To check on this, two additional groups were presented with 36 weeks and the 3 violation condition; one group received the parenthood instruction and the other did not. In the group that received the instruction the proportion of participants deciding to apply for the job was .10, the same as in the table. In contrast, the proportion for the group without the instruction was .60, which is not significantly different from the other proportions in the row and is the same as the other proportions in the column. Recall, however, that the parenthood instruction was included specifically to highlight the importance of "as little travel as possible" lest we observe too few rejections to detect thresholds. So, a proportion of .60 acceptances without the instruction is perhaps lower than might be expected, suggesting that the parenthood instruction does not fully account for the anomalous result in that cell of the table. Instructions aside, the constellation of 36 weeks of required travel and two other violations is bad news for the target job. Conclusions Future research should examine the conditions that influence the size of violation thresholds, such as the importance of the feature, the clarity of the difference, as well as individual differences. The latter are amply evidenced in the data for both of our experiments. References
|
||
|
|
||
|
Cognitive Errors as a By-product of Narrative Thought
Lee Roy Beach
Abstract
The Theory of Narrative Thought (Beach, 2010) is proposed as a means of accounting for many cognitive errors. I begin with a brief description of the theory and summaries of research on errors of memory (Schacter 1999; Loftus, 2005) and errors of judgment and reasoning (Kahneman, 2011). Then I demonstrate how the errors are interpreted within the framework of the theory, specifically as by-products of how narratives are constructed, revised, and used. The implications of errors for generating valid expectations about the future and for undertaking appropriate action when it is needed are discussed along with observations about the current absence of convenient methods of avoiding errors and about the limits of the theory.
The psychological literature contains a lengthy list of errors of human memory, judgment, and reasoning. Daniel Schacter (1999), in reviewing memory errors, has suggested that the errors are a “by-product of otherwise desirable features of human memory.” Elizabeth Loftus (2005), reviewing question-induced memory errors, has made a similar suggestion, as has Daniel Kahneman (2011), in his review of errors of judgment and reasoning. The purpose of this article is to describe a theory of cognition that encompasses cognitive errors as the natural by-product of an otherwise highly adaptive and useful way of thinking, called narrative thought.
On the assumption that most readers are unfamiliar with it, I will begin with a description of the Theory of Narrative Thought. Then I will briefly describe the main points of the three reviews of error research cited above and describe how at least some of those errors can be accounted for as by-products of normal, everyday narrative thought. In the process, I will attempt to show how the errors come to corrupt narratives, resulting in false expectations and inappropriate, often counterproductive, action.
Narrative Thought
Based upon the work of Walter Fisher (1987), in communications, and Jerome Bruner (1986; 1990), in cognition, the Theory of Narrative Thought (Beach, 2010, 2011) posits that everyday thought is in the form of narratives, which are causally motivated, time-oriented “stories” that give continuity and meaning to ongoing experience and permit predictions about the future. Because the future has not happened yet, the predicted future can be evaluated for its potential desirability; if it falls short, action can be taken to move things in a more desirable direction. When the narrative is reasonably accurate, this process ordinarily works well. But, when the narrative contains errors, ongoing experience may be misinterpreted, predictions about the future may be inaccurate, and action based on those predictions may be inappropriate.
Although narratives are stories, they are not simply interior monologue or the voice in your head, nor are they simply words, like a novel or a newspaper article. They are a rich mixture of memories and current visual, auditory, and other aspects of awareness that capture experience far better than mere words can ever do. They provide a contextual background and temporal continuity against which ongoing experience unfolds.
You have many narratives in play concurrently, one for each area of your life, and you can switch back and forth among them. The narrative that is the focus of attention at the moment is called the current narrative, the story that gives meaning to the present by providing context; what has led up to this moment, what is happening now, and, by extension, what will happen next. In short, by contextualizing your experience, the current narrative provides you with peace of mind because you understand what is going on.
The elements of narratives are symbols that stand for real or imagined events and actors (either animate beings or inanimate forces), including you, which are bound together by causality and implied purpose. The narrative itself is a temporal sequence of events that are purposefully caused by animate beings or are the result of inanimate forces. Temporal refers to subjective time, not clock time. Narratives are similar to novels and movies in that they maintain sequentiality but are flexible about duration.
Causality and implied purpose result from causal rules that govern how the narrative is structured. Past experience and extensive instruction have stocked your memory with a variety of rules and the conditions under which they apply. Although there are only two general classes of rules, causal and normative, there are many instances of each class because the specifics of each instance are singularly relevant to a particular narrative element.
Rules in the first class, causal rules, are of the if→then form. What-to-expect rules are, “If X happens then Y will happen.” What-to-do rules are, “If I (or someone or something) do X, then Y will happen.” Both rules are cause and effect and both allow for their converse, “If Y is observed, then X must have caused it,” and, “If Y happened, then I (or someone or something) must have done X to cause it” (Beach, 1973).
Both the structure of the past and present portions of your narrative and the structure of the future that is their extension are governed by what-to-expect rules. This means that when X and Y are elements of the narrative, they are bound by the causal rule, X caused Y. If only Y is an element, it is bound to some event from memory, X, that is likely to have caused it. There may be multiple Xs and Ys in a rule, but however many there may be and whichever way the rule runs, from Xs to Ys or from Ys to Xs, it is the causal links between Xs and Ys, as well as between these elements and past experience, that makes the narrative coherent. As we shall see, coherence is one of three subjective criteria for a “good” narrative.
What-to-expect rules also govern extension of the past and present into the future. Thus, if X is an element of the narrative, it serves as a memory probe for retrieval of a relevant what-to-expect rule. The rule tells you that because X is part of the past and/or present, Y can be expected to be part of the future. Rules in the second class, normative rules, are about how things ought to be, your values. They dictate what is and what is not desirable and therefore play a role in evaluating the expected future and deciding whether to intervene to improve expectations. Some normative rules are primary enduring imperatives, and some are secondary transitory preferences.
The apparent simplicity of rules is deceptive. In fact, each instance is a package of information about a specific agent performing a specific action to achieve a specific outcome. Partitions of these instances provide information about classes of similar agents, similar actions, and similar outcomes.
Forecasts
The future that is generated by your what-to-expect rules is called your forecast of the future. It is what you expect too happen if you do not intervene to make something else happen. The question is whether this forecasted future, when it arrives, will turn out to be desirable. If it looks as though it will be, you can simply continue doing what you are doing and let the future unfold “naturally”. If it looks as though the future, as forecasted, will be undesirable, as determined by your normative rules (values), you must intervene to divert the flow of events in a more desirable direction.1 Interventions are guided by what-to-do rules, in which the X in the “if X, then Y” is your action and the Y is a desirable outcome.2 Forecast evaluation and remedial intervention are discussed in detail in Beach (2010).
Memory
Immediate memory affords information about what is happening now, your current narrative. Episodic memory affords information about the rules that govern particular events and actors that are elements of the narrative; their unique motives, and their characteristic ways of behaving. Semantic memory affords information about the rules that govern how events and actors similar to those in your narrative generally are motivated and behave. And procedural memory affords information about rules that govern what to do about it all.
The narrative is constantly attuned to memories related to its elements, but targeted retrieval from memory usually is in response to forecast failure or in response to questions. Forecast failure means that you have failed to correctly forecast events (i.e., you are surprised); the failure prompts you to search memory to find information, largely in the form of rules, with which to revise your narrative in an effort to improve future forecasts. When you are asked a question, your answer is a forecast about what will satisfy the person who asked. If you do not have an answer in your narrative, you must probe memory to find one, which is then integrated into your narrative and issued as a forecast. Either in response to a forecast failure or a question, only the details of a memory that are pertinent to the needed response are retrieved, otherwise there would be an unmanageable flood of largely irrelevant information; where “needed response” means that admissible retrievals are constrained by their links to the elements of the narrative. As a result, memories, even those reported as (and believed to be) exhaustive and accurate, are always somewhat incomplete and always reflect the narrative that is in play at the moment.
Good Narratives
A “good” narrative is simple, coherent, and plausible. It is simple when it contains only enough elements and relationships to give meaning to experience and to produce expectations about the future. It is coherent when its events (effects) are congruent with the actions (causes) of its actors. It is plausible when the actions of its actors are congruent with their own or similar actors’ actions in the past and are appropriate to the situation. The more simple, coherent and plausible a narrative is, the more you believe it to be a valid story of your experience and a valid depiction of the situation in which experience is taking shape. In short, the simpler and better the story you tell yourself, the more you believe it to be true.
Unfortunately, a simple, coherent, and plausible narrative, however true it may seem, may in fact be flawed. However, unless someone or something reveals the flaws or unless the future turns out to be significantly different from what you expected, you have no reason to doubt your narrative. But, when the narrative is shown to be flawed, the necessity for accurate future forecasts demands that it be revised. Disconfirming information is important for forecast revision, but so is confirming information. You are particularly attuned to confirming information because it bolsters the narrative’s plausibility, making it even more believable. Moreover, confirming information, being redundant, may not need to be incorporated into the narrative, other than recording the fact that it was received, thus keeping the narrative simple. Narratives are all you have to make sense of your experience—they are your truth—so positive feedback strengthens your belief that you understand what is going on and that your forecasts can be trusted.
Narrative Revision
Revision is the mechanism by which corrective information is incorporated to a narrative when a forecast fails. Failure occurs when the forecast was wrong because the narrative was wrong or because someone or something changed the environment after the forecast was made. In either case the narrative does not appropriately represent the environment and must be up-dated to prevent future forecast failure. Recall that your episodic and procedural memories contain a large store of causal rules reflecting your past experience with a variety of actors and actions. When a forecast fails, the differences between what was expected and what actually happened serve as probes for retrieving pertinent rules from memory. Because the failed forecast derives from the content of your narrative, the differences between forecast and what happened reflect, in part, the contents of your narrative, but they also reflect, in part, the aspects of the environment that made your forecast fail. This means that when the differences are used to probe memory, what is retrieved will partly reflect the narrative’s content and partly reflect the status of the environment, so the retrieved information will not be identical to that which already is part of the narrative. Revision consists of replacing the old information with the new and making a new forecast (not for when the forecast failed, which is water over the dam, but for the future that starts right now). If the new forecast fails, the differences between it and what actually happened are used to retrieve yet other instances of rule-related information from memory. This is substituted into the narrative, another forecast is made, and so on. This feedback mechanism usually brings your narrative into closer alignment with what is happening around you; closer, but never quite wholly aligned because the world is constantly changing as a result of your actions and the actions of other actors and forces. This mechanism also is the way you up-date the contents of your memory; information from the narrative is retained as a series of episodes in episodic memory, which is how you are able to remember what happened a few moments ago or a day ago or a year ago.
Two Kinds of Narratives
The discussion thus far has been about only one kind of narrative, called chronicular narratives, but there is a second kind, called paradigmatic narratives. Chronicular narratives are your customary way of thinking but, because their function is to make sense of your moment by moment experience, the emphasis is on agility rather than precision. As the world changes, if only because you and others are alive and functioning in it, a forecast made a moment ago is quickly outdated, so the narrative must rapidly be revised in an effort to ensure that the next forecast is more up-to-date. The result is a never-quite-successful effort to keep current and, usually, a willingness to settle for approximations rather than an insistence on getting everything exactly right. Striving for a high degree of precision would slow things down, create a backlog, and ultimately overwhelm your ability to understand what you are experiencing.
But, even in a fast paced world, approximations are sometimes not good enough. When the situation demands that the forecast be particularly accurate, time must be taken, and an effort made, to increase the precision of the chronicular narrative, which can be difficult to do.
Part of the difficulty is that making a narrative and its forecast precise often requires use of quantities, something that chronicular narratives do not do well. Without resorting to counting, narrative numeration is primitive, something like 0 to 5, and commensuration is crude; something like “a lot less, less, equal, more, and a lot more.” Moreover, use of even these primitive quantities in any but the most rudimentary calculations is beyond the scope of narrative thought.
The other part of the difficulty is that while we appear to be born with a mechanism for adjusting our chronicular narratives to accommodate received information (called learning), we do not appear to come equipped with a complementary mechanism for active procurement of information. Indeed, beyond very simple trial and error experimentation or merely asking someone else, we have to be taught how to search for the information our narratives need.
Just as we humans have invented tools to extend and improve our limited physical abilities (levers, pulleys, pencils, hammers, etc.), so too have we invented tools that extend and improve our limited chronicular narrative abilities. These tools, called paradigms (Bruner, 1986; 1990), are narratives but they are ancillary to, and subordinate to, chronicular narratives. Part of procedural memory, they are the methods you have learned, sometimes through experience but more often through being taught by others, for obtaining the specific information you need to improve your narratives in order to increase forecast accuracy.
For convenience chronicular narratives are referred to simply as “narratives” and paradigmatic narratives are referred to as “paradigms.”
Paradigms are procedures for performing a specific class of tasks, either intellectual or manual, the outcome of which is information that can be incorporated into a narrative. Examples of intellectual paradigms are how to count, do arithmetic, program a computer, produce grammatically correct sentences, navigate through a library or the internet, or apply the scientific method. Examples of manual paradigms are how to drive a car, operate a computer, iron a shirt, or use an electric drill.
Paradigms’ usefulness derives from their precision (definitions and sequences of clear-cut steps), their ability to produce informative results, their repeatability, their applicability to classes of tasks rather than a single task, and their public nature—they can be taught to and learned from others who encounter the same tasks. Unlike our everyday narratives, paradigms are not limited to qualitative, casual logic and rudimentary numeration and commensuration; they can deal with quantity, precise measurement, and non-causal relationships like correlation and contiguity. Moreover, unlike our everyday narratives, they are largely contentless. What content they have derives from the tasks to which they are applied. For example, grammar prescribes how to structure a sentence but not the content of the sentence, and certainly not what the sentence means. Similarly, when its assumptions are met, probability theory, which is a paradigm, can be applied to a range of events without reference to what or who they are as individuals; something a narrative could never do.3
For all of their usefulness, paradigms have their drawbacks. They are useful only if you realize that you need to use one, only if you know which one to use, only if you have that one in your repertory, and only if you use it correctly. Moreover, their use requires time and effort, neither of which may be available as you rush to keep up with a rapidly unfolding course of events. So, even if a paradigm would be useful, there may not be an opportunity to benefit from that usefulness. The upshot is that, in the normal course of things, you must make do with the limited qualitative, causal reasoning that narrative thinking affords. Sometimes this is sufficient, but sometimes it is not.
Narrative Errors
The foregoing paints a picture of you and me as somewhat encapsulated in our own narratives. As long as a narrative is simple, coherent and plausible, we believe it is a true account of how the past led to the present and extrapolates to the future. With this belief comes a reduction in uncertainty and an increased peace of mind that everything is under control. Of course, believing that our narrative is true does not guarantee that it is, but unless we receive evidence to the contrary, we persist in our belief.
When the future does not turn out as you expected, you need to figure out what went wrong so you can create more realistic expectations. Minor failure due to routine environmental change is easily accounted for and the revisions necessary to represent them in your narrative are reasonably easy; you expect a little change and adapt to it quickly. A major change may require more extensive revision, but unless it is utterly jarring (like the unexpected death of one of the narrative’s central actors) it usually can be accommodated rather easily. But, small or large, forecast failure indicates that your narrative contains errors and must be revised so you can stay apace with environmental change or your future forecasts will become increasingly inaccurate.
Sources of Error
The existence of a narrative error raises the obvious question: Where did it come from? In what follows, I will attempt to answer this question and, in doing so, I will attempt to show how error is intrinsic to narrative thought. To begin, it is convenient to label the sources of error: misinformation, misremembering, and mistakes in reasoning.
Misinformation
Misinformation results from both honest mistakes and the intention to mislead. Honest mistakes occur when a trusted source provides erroneous information in the belief that it is correct. Intentionally misleading information is meant to bias the recipient’s behavior, usually in a way that will profit the provider; e.g., propaganda favors the government, advertising favors the sponsor, lying favors the liar.
For narratives, receipt of misinformation is a special case of information receipt in general. At the core of most human interactions is an attempt to influence the other person’s narrative by providing new information about its actors and their motives or new interpretations of their relationships. Sometimes the attempt is quite direct, for example, when a friend tells you that your version of events is wrong and what it should be instead. Sometimes it is more subtle, for example, when a trusted friend contrasts his or her forecasts with yours, leaving you to figure out where you went wrong. An information source can be another person or the media, reference works, or prevailing opinion.
When information is received, you must decide whether or not to incorporate it (believe it) into your narrative. To some extent, this depends upon how much your narrative leads you to trust the source. But even when source is trusted, the new information must be plausible. That is, you must be able to retrieve instances of rules that could conceivably produce the outcome (the information) that the source provided. When incorporated, plausible information often leaves the fundamental structure of your narrative in place, preserving its simplicity and plausibility, and, perhaps, even increasing its coherence. The ideal information is both plausible and allows the least revision while making the narrative better. For these reasons, confirming information is the very best information (Oswald & Grosjean, 2004).
Intentionally introduced misinformation, lies, is a major source of narrative error. Like sin, there are lies of omission and lies of commission. Lying by omission is lying by withholding information, which leaves the recipient with a flawed narrative that produces forecasts and behavior that serve the purposes of the liar. Lying by commission is lying by providing misinformation, which prompts the recipient to revise his or her narrative in a way that serves the purposes of the liar. Lying by omission is generally regarded as less serious than lying by commission. Even less serious are the little “white lies” that grease the skids of social intercourse; the empty complements, the attempts to avoid hurting the other person’s feelings, and so on. Ultimately, however all lies are designed to manipulate the other person’s narrative, their forecasts, and thus their behavior.
Much of the research on misinformation has focused on the effects of leading questions: Misleading questions, which contain information designed to influence the answer, e.g., referring to a previously viewed film of a fender-bender auto accident, “How fast were the cars going when they crashed together” (Loftus & Palmer1974)? Artful questions, which contain crucial but easily overlooked or readily misinterpreted information, e.g., “True or false: All roses are flowers; some flowers fade quickly; therefore some roses fade quickly” (Kahneman, 2011)? (The correct answer is False.) We will examine misleading questions here and artful questions when we discuss mistakes in reasoning.
The research on misleading questions has focused on the misinformation effect; apparent distortions of memories of past events by exposure to misleading questions. Loftus (2005) summarized the findings: Older memories are apparently distorted more than recent memories; warnings given before the misinformation is introduced sometimes reduce apparent distortion but have no effect if given afterward; reports of distorted memories are qualitatively different from those for undistorted memories; under the proper circumstances, people can be led to believe they remember things that never happened to them, although, again, the reports are different from reports of things that actually happened; it is not yet unclear whether distorted memories permanently replace original memories.
At the end of her summary of the research findings, Loftus says, “An obvious question arises as to why we would have evolved to have a memory system that is so malleable in its absorption of misinformation. One observation is that the “updating” seen in the misinformation studies is the same kind of “updating” that allows for correction of incorrect memories.” (p. 365).
The underlying structure of any question is an adverb, a subject, and a verb. The adverb is the interrogative that alerts the listener that a question is coming (who?, what?, when?, where?, how?), the subject is the context for the question, and the verb specifies the form the answer is to take. Thus in the question, “How fast were the cars (in a film) going when they crashed together,” “How” says a question is coming, the crashing cars are the context, and “fast” specifies the answer is to be in miles per hour. Misleading information usually is contained in the question’s context. In our example, “crashed” creates a different context than, say, “bumped”. This information is designed to become part of the listener’s narrative about what is going on, “I am being asked a question about the crashing cars I saw in the film,” which creates a different narrative than “the bumping cars” would have. If the context is not jarringly different from the context in your memory of the film, the new context will be treated as clarifying information from a trusted source and incorporated into the narrative. If the narrative does not contain the specific answer to the question about speed, you can infer it from the narrative itself, which now has been shaped by “crashed.” If the question’s context had been jarringly different from the memory (if the cars in the film had been going very slowly so crashing is an implausible descriptor), the question’s context would have been regarded as erroneous and probably not have been incorporated into the narrative. If it had not been incorporated, the answer to the question would reflect whatever was in the narrative before the question was asked.
As time passes, what is current in the current narrative becomes the past and is stored in episodic memory. Thus, when a narrative is updated to accommodate new information and then moves into your memory, either of two things can happen. Either the new version of the memory replaces the old version, which is what is generally assumed in the distorted memory literature, or the new version is stored as a different version of the old memory, leaving you with two versions of the memory. Narrative theory favors the latter because reports of “distorted” memories are qualitatively different from reports of “undistorted” memories (Loftus, 2005), suggesting that people are, however vaguely, aware that they remember two versions of the event, one a revision of the other. That two versions can exist is revealed by the common experience of being able to recall what you thought to be true before something happened to change your mind. For example, if you have a friend whose name you think is Ralph, a name by which you have addressed him on more than one occasion, and you find his name actually is Rafe, you must revise this detail in your narrative and store the revision away in your memory. Now you have two memories, the original in which you thought his name was Ralph and a new one in which you think his name is Rafe. If I asked you his name, you would reply with the update, not the original; perhaps with a bit less confidence than if you did not have two versions of the memory. Over time, of course, the original memory may fade because you have no need for it, but if you are sufficiently embarrassed about having addressed him by the wrong name, the original may remain strong. In fact, you may even use “Ralph” as a prompt for “Rafe,” leaving you vulnerable to slipping up and calling him Ralph again.
Misremembering
Schacter (1999) identified six types of misremembering. The first three are types of forgetting: “Transience involves decreasing accessibility of information over time, absent-mindedness entails inattentive or shallow processing that contributes to weak memories of ongoing events or forgetting to do things in the future, and blocking refers to the temporary inaccessibility of information that is stored in memory” (p. 183).
The second three are different types of mistaken memories: “Misattribution involves attributing a recollection or idea to the wrong source, suggestibility refers to memories that are implanted as a result of leading questions or comments during attempts to recall past experiences, and biases involves retrospective distortions and unconscious influences that are related to current knowledge and beliefs” (p. 183).4
Schacter notes that it is tempting to view memory errors as “flaws in a system design or unfortunate errors made by Mother Nature during the course of evolution” (p. 183). Instead, echoing Anderson & Schooler (11991) and Bjork and Bjork (1988), he suggests, as Loftus (2005) did, that it is more useful to view them as by-products of otherwise desirable features of human memory. Transience reflects the necessity “…to forget information that is no longer current, such as old phone numbers or where we parked the car yesterday. Information that is no longer needed will tend not to be retrieved and rehearsed, thereby losing out on the strengthening effects of postevent retrieval and becoming less accessible over time” (p. 196). In absent-mindedness, events that receive minimal attention have little chance of being recalled. On the other hand, “…if all events were registered in elaborate detail ...the result would be a potentially overwhelming clutter of useless details” (p. 196). Blocking “reflects the operation of inhibitory processes in memory …a system in which all information that is potentially relevant invariably and rapidly springs to mind …would likely result in mass confusion” (p. 196).
Misattributions reflect “… a memory system that does not routinely preserve all the details required to specify the exact source of an experience. But what would be the consequences of retaining the myriad of contextual details that define our daily experiences? …How often do we need to remember all the precise, source-specifying details of our experiences?” (p. 197).
Similarly, “…misattributions involving false recall and recognition concerns the distinction between memory for gist and verbatim or specific information. …[M]emory for gist may…be fundamental to such abilities as categorization and comprehension and may facilitate the development of transfer and generalization …which is central to our ability to act intelligently and constitutes a foundation for cognitive development” (p. 197).
Forgetting is largely a retrieval problem and is not addressed by narrative theory, although Schacter’s comments are not at variance with the theory. One of Schacter’s three kinds of mistaken memories, suggestibility, which is the effects of outside influences, was discussed above under leading questions. The second, misattribution, pertains primarily to attributing something you remember to an incorrect source or forgetting the source of an idea that you might come to think of as your own or “remembering” something that never happened. We will discuss misattribution as it is more commonly viewed when we discuss mistakes in reasoning.
About bias, the third of his three kinds of mistaken memories, Schacter says “…relevant to many instances of bias [is the influence] of preexising knowledge and schemas. Although they can sometimes contribute to distorted recollections of past events, schemas also perform important organizing functions in our cognitive lives (Mandler, 1979). Schemas are especially important in guiding memory retrieval, promoting memory for schema-relevant information, and allowing us to develop accurate expectations that are likely to unfold in familiar settings on the basis of past experience in those settings (Alba & Hasher, 1983)” (p. 197). The resemblance to narratives is straightforward.
Schacter, citing Reyna & Brainerd (1995), distinguishes between memory for gist and verbatim memory, saying, “False recall and recognition often occur when people remember the semantic or perceptual gist of an experience but do not recall specific details.” (Pl 197). Memory for gist makes sense in terms of narrative thinking. For the most part, attention is focused on the narrative’s main story line, the plot, which involves the primary elements—the principle actors and their relationships. But a story line requires a background against which to play out. The background consists of secondary elements—the supporting actors, their interrelationships, and their relationships to the primary elements. In the interest of narrative simplicity, these secondary elements need not be richly rendered, only the gist is needed. The result is, as the present becomes the past, the memorial record of these elements will be the gist that the narrative required. Gist memories, old memories, and unrehearsed memories are “weak memories.”
Because they are gist in the narrative and passed on as gist in memory, you possess few retrievable details about secondary elements. But, if it is demanded, you can use the rest of the narrative to elaborate upon the gist. The elaboration may be quite convincing, both to you and to others, but it is not necessarily accurate. This story-telling should not be surprising; after all, stories are the essence of narratives. And, because we believe our narratives, we often believe the fictional detail we create. This is one of the dangers of pressing witnesses to supply detailed descriptions of events that they viewed only briefly or that had only peripheral importance at the time; they will do it, and maybe even believe it, it but it is likely to be wrong.
Mistakes
The literature on mistakes in reasoning consists of two rather separate bodies of research. One is research on errors arising from misattributions of the causes of observed events. The other is research on errors arising from faulty or inappropriate reasoning.
Misattribution
Research on attribution can be divided into inferences about what caused an observed event and inferences about the motive for causing it (Gordon & Graham, 2006). To greatly oversimplify what is a nuanced and somewhat controversial literature (Sabini, Siepmann, & Stein, 2001), the primary finding, called the fundamental attribution error, is a tendency to favor dispositional explanations of other people’s, particularly strangers’, actions over explanations favoring situational demands. The complementary tendency is to favor situational explanations of one’s own actions and the actions of people about whom one has a good deal of knowledge. The controversy is about the strength and universality of this tendency, as well as about why it happens.
Recall that causality is intrinsic to narratives. Recall also that you believe that your narrative is true and that a forecast based on it is true. Therefore, if the forecast fails, you default assumption is that it must be because someone or something changed the environment in a way that caused the failure. Frequently you can merely settle for recognizing that the change took place, but to forecast future changes by this same someone or something you need to revise your narrative to include who or what did it and why. Active investigation, even just asking questions, is time consuming and you seldom have time. Inference (which is what attribution is) is faster and its results are in the language of narratives: who or what caused the change and for what purpose?
Who or what did it? When your forecast fails, if you did something that may have caused it, your actions and the results are easily incorporated into your narrative. If you did nothing that could have caused it, you attribute your good or bad fortune to the most plausible external animate or inanimate agent. When it is not apparent that anything you or a plausible agent did to cause the unexpected event, you tend to attribute it to some amorphous external force like good or bad luck, good or bad karma, or Providence. What was the purpose? Attributing motive takes a little more effort, but again you tend to do what is fastest. Because your narrative already contains the situational demands that prompted you to do what you did, it is easy to attribute your actions to those demands.
In contrast to your insight about the demands being made upon you, unless your narrative already contains information about them or unless they are very straightforward (He was forced to do it by his mother, boss, parole officer) you may not know much about the demands on an external agent, particularly a stranger. Active investigation takes time and it is faster to attribute the agent’s actions to his, her, or its dispositions. Moreover, dispositions have the advantage that they usually can be represented in narratives by simple, short-hand labels such as anger, sadness, hope, generosity, intelligence and so on. Simple labels keep your narrative simple and may even increase its coherence and plausibility. Incorporating complex situational demands into a narrative might be the prudent thing to do, it might even increase its plausibility, but all the details are likely to decrease its simplicity and coherence, decreasing your belief in its accuracy and therefore, decreasing your peace of mind.
Reasoning
In his book, Thinking Fast and Slow (2011), Daniel Kahneman brings together over 50 years of research in which he and many other researchers, especially the late Amos Tversky, asked people artful questions that require logical thinking and statistical inference and compared their answers to the answers provided by the appropriate logical or statistical paradigm.5 The researchers call a mismatch between the two answers a “cognitive error,” but because all of the errors we have been discussing are cognitive, we will refer to it as a mistake in reasoning. As Kahneman makes clear, the mistake is not the erroneous answer itself, it is the reasoning that led to the erroneous answer.
To facilitate his discussion, Kahneman poses two “fictional” systems. System 1 corresponds roughly to the unconscious mind and intuition. System 2 corresponds roughly to the conscious mind and rationality. “System 1 operates automatically and quickly, with little or no effort and no sense of voluntary control” (p. 20). “System 2 allocates attention to the effortful mental activities that demand it, including complex computations. The operations of System 2 are often associated with the subjective experience of agency, choice, and concentration” (p. 21).
System 1 effortlessly originates the “…impressions and feelings that are the main sources of the explicit beliefs and deliberate choices of System 2 …but only the slower System 2 can construct thoughts in an orderly series of steps” (p. 21). Underlying much of the discussion of System 2 is a concept of rationing; attention and mental effort can be depleted and System 2’s rationality depletes them quickly. Therefore, System 2 resists undue expenditure. Moreover, low expenditure promotes cognitive ease, which is pleasant, and the easiest way of achieving it is for System 2 to uncritically accept whatever it is offered by System 1.
Together, the rather frenetic System 1 and the rather lazy System 2 form “a machine for jumping to conclusions” (p. 79). This is not necessarily bad: “Jumping to conclusions is efficient if the conclusions are likely to be correct and the costs of an occasional mistake acceptable, and if the jump saves much time and effort. Jumping to conclusions is risky when the situation is unfamiliar, the stakes are high, and there is no time to collect information. These are the circumstances in which intuitive errors are probable, which may be prevented by a deliberate intervention of system 2” (p. 79). Unfortunately, System 2 often fails to intervene, if only because, in its laziness, it fails to recognize that doing so is appropriate.
The essential idea is that System 1 continuously monitors what is going on, both in the environment and in your mind, and effortlessly generates assessments of the situation: similarity, representativeness, causality, and availability of associations and exemplars. When questions are encountered that require logical or statistical reasoning, lazy System 2 often uses whatever answer System 1 supplies, even an illogical answer. Even worse, when System 1 does not have a ready answer to the question, it supplies an answer to a simpler question to which it does have an answer, and System 2 accepts it. The answers to the simpler question usually derives from associative and emotional coherence, mood, feeling intensity, liking/disliking, and so on, rather than anything resembling deliberative reasoning. Thus, if you were asked to judge the relative riskiness of flying versus driving your car to some distant city, lacking an appreciation of statistics, your System 1 might answer the question by appraising how much control you feel when flying versus how much you feel when driving. Thus, the answer is based on a comparison of feeling intensities about control, which, were it on the job, your System 2 would condemn as irrelevant to a question about risk—a statistical question. Your System 2 might step in if your judgment were challenged but, for most of us, it would not have the necessary statistical sophistication to do much better than System 1 did. Moreover, like retrieved memories, System 1’s answers are compelling.
As in the example about flying, many of the most noteworthy findings of the cognitive errors research result from failure to appreciate the statistical nature of the question. Another example is the so-called “Law of Small Numbers.” The idea is that most people believe that, no matter what their size, samples resemble the population from which they are drawn and therefore are suitable for drawing reliable inferences about the population. This is in contrast to the statistical Law of Large Numbers, which says that larger samples are more likely to produce reliable inferences. The law of small numbers does not derive from misapplication or misunderstanding of statistics, it has nothing to do with statistics at all. System 1 has no concept of sampling, sample size, randomness, or any of the rest of the statistical framework; the question about a sample’s validity is generally meaningless to it. Instead it operates on causality: the population “causes” the sample (population→sample) so the sample, whatever its size, must reflect its cause.
Base rate errors also demonstrate the application of causal logic instead of statistical logic. For example, most of us think someone described as quiet and studious is more likely to be a librarian than an engineer. Statistical reasoning turns on two points: First, there are more engineers in the world than librarians (base rates) and, second, the person in question was randomly drawn from the population of librarians and engineers. Neither base rates nor randomness, the antithesis of causality, exists for System 1 and may only exist for System 2 if it has been trained in statistics. Instead, System 1 bases its judgment on “representativeness,” the similarity between the person’s characteristics and stereotypes of librarians and engineers, perhaps bolstering it with a causal story along the lines of the person, believing that he would be more comfortable around brainy, gentle librarians than around can-do, rough-and-ready engineers, decided to become a librarian.
Kahneman’s account of Systems 1 and 2 sounds much like Schacter’s account of schemata and our account of narratives: “The main function of System 1 is to maintain and update a model of your personal world, which represents what is normal in it. The model is constructed by associations that link ideas of circumstances, events, actions, and outcomes …[that] determines your interpretation of the present as well as your expectations of the future” (p. 71). “We are evidently ready from birth to have impressions of causality …They are the products of System 1” (p.76, italics his). “System 1 can deal with stories in which the elements are causally linked, but it is weak in statistical reasoning (p. 170). In short, “people are prone to apply causal thinking inappropriately, to situations that require statistical reasoning. Statistical thinking derives conclusions about individual cases from properties of categories and ensembles.Unfortunately, System 1 does not have the capability for this mode of reasoning; System 2 can learn to think statistically, but few people receive the necessary training” (p. 77).
Kahneman’s fictional System 1 and System 2 do not correspond exactly with narrative theory’s chronicular and paradigmatic thinking. This is because System 1, being frenetic unconscious intuition, is perhaps too mystical and System 2, being lazy conscious deliberation, is perhaps too rational. The correspondence is much cleaner with the forerunners of Systems 1 and 2, epistemic and aleatory reasoning (Kahneman, Slovic, & Tversky, 1982; Tversky & Kahneman, 1983).6 Chronicular narrative thinking corresponds to epistemic thinking and paradigmatic narrative thinking corresponds to aleatory thinking (Beach, 2011).
Epistemic thinking, the predecessor of System 1, involves the unique properties of events as well as information about the conceptual systems in which they and their properties are embedded. Aleatory thinking, the predecessor of System 2, is the logic of gambling and probability theory (an aleator is a dice player). Aleatory logic regards all events in a particular set as mutually intersubstitutable so that statements about the characteristics of any event are based on its class membership rather than on its unique properties. Barnes (1984) investigated the aleatory/epistemic distinction in judgments and reasoning research and concluded that when an experimenter adopts aleatory (paradigmatic) logic as the standard of correctness, but the participants in the experiment think epistemically (narratively), which they almost always do, differences are to be expected.
This raises a question about how people, while thinking narratively, make probability judgments at all. Certainly, the word “probability” is commonly used, as in “It probably will rain tomorrow.” Kahneman suggests that these judgments reflect the degree to which we believe our stories about the events. But …“The most coherent stories are not necessarily probable, but they are plausible, and the notions of coherence, plausibility, and probability are easily confused by the unwary.” (p. 159, italics his). In this Kahneman and narrative theory agree; probability judgments are not about the event in question; they are about the plausibility of the narrative that forecasts the event. The logic of narratives is causality and, without training, the statistical concept of probability is foreign. When you say that you think something is probable, you ordinarily mean that it is plausible that the event in question will happen given what you know about what is going on and your expectations about what will happen in the future. This substitution of plausibility for probability makes sense within narrative theory, but it makes no sense in terms of probability theory. In Kahneman’s view, “The uncritical substitution of plausibility for probability has pernicious effects on judgments when scenarios are used as tools of forecasting” (p. 159). Perhaps so, but even the statistically sophisticated make frequent errors when answering Kahneman’s questions; perhaps plausibility makes more sense to them, and to the rest of us, than statistical probability. After all, one of the most common definitions of probability is the limit of an infinite number of random draws from a defined population of events; not the stuff of intuition.
As Barnes’ (1984) experiment suggests, in retrospect the results of research on mistakes in reasoning are not surprising. After all, the paradigms, which supply experimenters with the correct answers to their questions, exist solely because narrative thought cannot deal precisely with the kinds of questions the experimenters are asking. If it could, there would be no need for paradigms in the first place and there would be no need for experiments or experimenters. We would all be proficient intuitive statisticians, intuitive physicists, intuitive logicians, and so on. But, we are not, so paradigms have evolved as tools for extending our thinking. They tell us how to do the tasks that need doing and how to answer the questions that need answering so that narrative thought can get on with its business.
Of course, failure to use the appropriate paradigm to supply the information needed for a narrative will introduce error into the narrative and subsequent actions. But, Kahneman is right, narrative thinking (in its guise as System 2) often fails to recognize its own limits and fails to turn to the needed paradigm to produce required information. But nobody has yet come up with a reliable way of helping us recognize when we should resort to narratives.
Discussion
We began our search for the origins of narrative error by examining their sources: misinformation, misremembering, and mistakes in reasoning. Following the suggestions of the reviewers of the research in these areas (Loftus, 2005; Kahneman, 2011; Schacter, 1999) we interpreted the errors as by-products of the everyday workings of narrative thought. Some errors can be interpreted as by-products of the narrative revision process and some as the by-products of the causal reasoning that underlies narrative thinking. In all cases, the result is an erroneous narrative, with the attendant danger of erroneous forecasts and erroneous actions.
Narrative revision is the process by which information is incorporated into narratives to keep them abreast of changes in the environment. Failure to correctly anticipate events means that the underlying narrative either lacks essential information or contains incorrect information. Either way, forecast failure triggers revision, using information derived from the particulars of the failure to identify and replace the narrative’s incorrect elements (events, actors, purposes, and relationships). In most cases this process successfully updates the narrative. In other cases, when the replacements are themselves erroneous, the error is compounded.
Misinformation is correct information withheld or incorrect information provided by an external source; either of which is an unintentional or intentional lie the use of which in narrative revision introduces error rather than correcting it. Misremembering is either the failure to retrieve information from memory (forgetting) or the failure to retrieve the right information. The former, like withheld information, prevents the appropriate revision of the narrative and the latter, like a lie, introduces even greater error.
Mistakes in reasoning are of three kinds. 7 First are mistakes due to misattributions (incorrect inferences) about the causes of forecast failure and consequent erroneous revision of the narrative. Second are mistakes due to reliance on the narrative’s intrinsic causal logic when a paradigmatic alternative is more appropriate. Third are mistakes that appear to be by-products of other aspects of narrative thinking, for example our persistence in the belief that our narratives are true. About this, the “illusion of validity,” Kahneman (2011) says: “… subjective confidence …in our opinions reflects the coherence of the story …[we] …have constructed. The amount of evidence and its quality do not count for much, because poor evidence can make a very good story. For some of our most important beliefs we have no evidence at all, except that people we love and trust hold these beliefs. Considering how little we know, the confidence we have in our beliefs is preposterous—and it is also essential” (p. 209). Such confidence is essential because, if we doubt our stories, we doubt our basic understanding of our own experience as well as our ability to control our lives and our futures—an existential dilemma.
Mistakes resulting from reliance on causal reasoning are important for reasons other than trying to avoid them. They tell us about the boundaries of narrative thought and, someday perhaps, how to know when to switch to paradigms. Actually, most of us know when to switch to paradigms for performing physical tasks; e.g., we know the futility of trying to loosen a tight screw with a fingernail file and go immediately to the appropriate paradigm for using a screwdriver. We even know when to switch to a paradigm for some cognitive tasks; we unhesitatingly apply our counting paradigm when our narrative requires a quantity. Similarly, we are quick to use simple arithmetic on our checkbook and an elementary form of geometry when parallel parking. But, even those of us who have long-time familiarity with statistics are slow to recognize the need to use it for the kinds of real life problems that researchers’ artful questions mimic, if only because the absence of causality in statistics will forever feel foreign and awkward. Those with less familiarity with statistics are even less inclined to switch to it; causal logic is familiar, comfortable and, most important, it works reasonably well. Probability is about classes of independent cases but narratives are about unique individual cases and their inter-relationships. It is difficult to reconcile the two kinds of information; resolution is usually accomplished by interpreting the probability information causality—which is why people persist in the face of admonishment to interpret correlation as causation.
Ease of recall and plausibility
Although statistical probability is not part of narrative thinking, uncertainty is. There appears to be two ways of appraising uncertainty, one appears to be about uncertainty about memories of events, ease of recall and the other appears to be about uncertainty about the truth of a narrative, plausibility. Ease of recall is referred to in the literature as “availability” (Tversky & Kahneman, 1973, 1974) and Kahneman (2011) cites plausibility as easily confused with probability by the unwary (p. 159). Ease of recall as a cue about uncertainty is, in fact, a very complex issue, depending on numerous variables, among which is the context in which retrieval and interpretation of the memory take place (Raghubir & Menon, 2005; Schwartz, Bless, Strack, Klumpp, Rittenauer-Schatka, & Simons, 1991). For narrative theory, the context is the narrative and, in the most straightforward circumstances, ease of recall reflects the differentiation between strong memories and weak memories. One thing that makes a memory strong is its frequency of occurrence as a narrative element; which is what memory theorists mean when they refer to rehearsal, and rehearsal makes the memory more easily recalled. A high frequency of occurrence in past narratives implies that the subject of the memory is something that comes up often in your life, so it is likely to come up again. When asked a question about a past event that requires an answer in the form of probability, which narrative thinking does not readily supply, ease of recall is a sensible way of attempting to satisfy the person who asked the question. Perhaps we should call this “available-probability.”
By the same token, plausibility is a reasonable way for narrative thinking to supply an answer to questions about an event’s probability. Plausibility means that you can see how the current state of affairs could lead to (cause) some event happening in the future or how an alteration in the current state could lead to it. It also includes the reverse, you can see how an observed event could have resulted from (been caused by) a previous state of affairs. Perhaps we should call probability assessments based on the narrative’s plausibility, “plausible-probability.”
Of course, both available-probability and plausible-probability are useful for more than merely providing answers to experimenters’ questions, they are how we evaluate uncertainty about future events and, thus, how much we believe our memories, our narratives, and our forecasts. It is not immediately clear how one would objectively demonstrate the adequacy of either kind of “probability” in everyday life, but, since they are fundamental to narrative forecasting, I suspect that most of us would be in constant trouble if they were seriously inadequate. To the degree that most of us survive and sometimes prosper, they appear to work reasonably well.8
Mitigation
The attempt to interpret cognitive errors as a by-product of narrative thought may strike some as an attempt to downplay their danger and to salvage the reputation of human cognition. Perhaps they are right on both counts. But, if so, what is the alternative? If errors are intrinsic to narrative thinking, are they so dangerous that we should all give up narratives and replace them with…..what? Rather than condemning narrative thought for its faults, we need to figure out how to mitigate those faults.
One viewpoint on mitigation is that it really is unneeded: because narrative revision is done on the run, it is more efficient to make the errors and hope they get purged in the long run as successive revisions are rapidly made. This viewpoint is willing to settle for a degree of inaccuracy in the cause of staying abreast of the flow of events.
A different viewpoint is that even the most cursory examination of the human condition produces numberless examples of misjudgment and illogic that have led to havoc and heartbreak. As a result, at the very least we should devise and disseminate error-avoidance techniques, perhaps making them part of basic education. As things stand now, however, we are reduced to admonishments to think critically and not to believe everything heard or read. I know from experience that repeated demonstrations and heartfelt warnings do not accomplish much. Indeed, Kahneman’s statement about mistakes in reasoning pretty much sums things up: “The best we can do is … learn to recognize situations in which mistakes are likely and try harder to avoid significant mistakes when the stakes are high” (p. 28).
Narratives’ strengths
Errors that are unattributable to revision or causal reasoning also tell us about narrative thinking’s other limits and its strengths. Narrative thinking may be weak when precision is required and when quantities must be manipulated and inferences drawn but it does well with metaphor, analogy, and other forms of reasoning by comparison or example. Its greatest strength, however, is its ability to impose continuity and coherence on what might otherwise be experienced as chaos and, in doing so, give us peace of mind. Depending on your viewpoint, this strength may be little more than a necessary evil. For example, Kahneman contends that, “The illusion that one has understood the past feeds the further illusion that one can predict and control the future. These illusions are comforting. They reduce the anxiety we would experience if we allowed ourselves to fully acknowledge the uncertainty of existence” (p. 204-205).
The counter-argument is that the proof is in the pudding. If we look past all the rhetoric about the pervasiveness of cognitive errors and the potential for dire consequences, causal reasoning and narrative thinking’s overwhelming record of successes justifies our belief that it provides understanding and allows us to predict and control our future. True, we all regret past mistakes, even as we know we will make more in the future, but in fact we get more things right than we get wrong. Insofar as you are not living on the street, panhandling for your daily bread, insofar as you succeed in at least some of your many aspirations and avoid most of the everyday dilemmas that could ensnarl you, your personal experience justifies your reliance on causal thinking and your faith in your narratives.
Narrative and mind
In closing, there is one big error that we must guard against, and I hope that admonition is sufficient. This is the error of equating narrative thought with mind, casting it in the role of an active, causal agent in the narrative about narratives. Narratives are only part of what we normally associate with word “mind,” not coincident with it. For example, strong emotions are a form of thinking that does not readily assume a narrative form; in the throes of passion—rage, lust, sorrow, joy, despair, love, hate—one does not care much about anything but the moment at hand, which is hardly the stuff of narrative. Later, of course, whatever was experienced and whatever happened may be incorporated into a narrative, but it will be a pale version of the original.
There are other aspects of thinking, other than passions, that are elusive to narration. While doing something routine--washing the breakfast dishes, driving to work—thoughts come to mind seemingly unbidden, out of the blue, unrelated to the current narrative. Similarly, artists, composers, writers and others who rely on the little-understood creative impulse, frequently speak of the mindlessness of the creative act—the almost automatic functioning that results in work that surprises even its originator. Even while we remember that narratives are only a part of thinking, we must be careful how we talk about them. It is convenient but inaccurate to say that a narrative actively guides attention or retrieval from memory. The narrative is just a story, it is passive, it is merely a part of the larger cognitive enterprise. While that enterprise may (or may not) require an agent such as an executive, a mind, or a soul to set things in motion, narrative is not that agent.
References
Alba, J. W., & Hasher, L. (1983). Is memory schematic? Psychological Bulletin, 93, 203-231.
Anderson, J. R., & Schooler, L. J. (1991). Reflections of the environment in memory. Psychological Science, 2, 396-408.
Barnes, V. E. (1984). The quality of human judgment: An alternative perspective. Unpublished doctoral dissertation. Seattle: University of Washington.
Beach, L. R. (1973). Psychology: Core concepts and special topics. New York: Holt, Rinehart, & Winston.
Beach, L. R. (2010). The psychology of narrative thought: How the stories we tell ourselves shape our lives. Bloomington, IN: Xlibris.
Beach, L. R. (2011). Cognitive errors and the narrative nature of epistemic thought. In W. Brun, G. Keren, G. Kirkeøen, & H. Montgomery (eds.), Perspectives on thinking, judging, and decision making: A tribute to Karl Halvor Teigen. Oslo: Universietsforlaget.
Bjork, R. A., & Bjork, E. L. (1988). On the adaptive aspects of retrieval failure in autobiographical memory. In M. M. Gruneberg, P. E. Morris, & R. N. Sykes (Eds.), Practical aspects of memory: Current research and issues (Vol. l, pp. 283- 288). Chichester, UK: Wiley.
Bruner, J. S. (1986). Actual minds, possible worlds. Cambridge, MA: Harvard University Press.Bruner, J. S. (1990). Acts of meaning. Cambridge, MA: Harvard University Press.
Fisher, W. R. (1987). Human communication as a narration: Toward a philosophy of reason, value, and action. Columbia, SC: University of South Carolina Press.
Gordon, L. M., & Graham, S. (2006). Attribution theory. Encyclopedia of human development (p. 142-144). Thousand Oaks, CA: Sage.
Hacking, I. (1975). The emergence of probability. New York: Cambridge University Press.
Kahneman, D. (2011). Thinking, fast and slow. NY: Farrar, Straus, & Giroux.
Kahneman, D., Slovic, P., & Tversky, A. (1982). Judgment under uncertainty: Heuristics and biases. New York: Cambridge University Press.
Loftus, E. F. (2005). Planting misinformation in the human mind: A 30-year investigation of the malleability of memory. Learning & Memory, 12, 361-366.
Loftus, E. F., & Palmer, J. C. (1974). Reconstruction of automobile distruction: An example of the interaction between language and memory. Journal of Verbal Learning and Verbal Behavior, 13, 585-589.
Mandler, J. M. (1979). Categorical and schematic organization in memory. In C. R. Puff (Ed.). Memory organization and structure (pp. 259-299). New York: Academic Press.
Oswald, M. E., & Grosjean, S. (2004). Confirmation bias. In R. F. Pohl (Ed.), Cognitive Illusions: A handbook on fallacies and biases in thinking, judgment and memory (pp. 79-96). Hove, UK: Psychology Press.
Raghubir, P., & Menon, G. (2005). When and why is ease of retrieval informative? Memory & Cognition, 33, 821-832.
Reyna, V. F., & Brainerd, C. J. (1995). Fuzzy-trace theory: An interim synthesis. Learning and Individual Differences, 7, 1-75.
Sabini, J., Siepmann, M., & Stein, J. (2001). The really fundamental attribution error in social psychological research. Psychological Inquiry, 12, No. 1, 1-15.
Schacter, D. L. (1999). The seven sins of memory: Insights from psychology and cognitive neuroscience. American Psychologist, 54, 182-203.
Schwartz, N., Bless, H., Strack, F., Klumpp, F., Rittenauer-Schatka, H., & Simons, A. (1991). Ease of retrieval as information: Another look at the availability heuristic. Journal of Personality & Social Psychology, 61, 195-202.
Tversky, A., & Kahneman, D. (1973). Availability: A heuristic for judging frequency and probability. Cognitive Psychology, 5, 207-232.Tversky, A., & Kahneman, D. (1974). Judgment under uncertainty: Heuristics and Biases. Science, 185, 1124-1131.
Tversky, A., & Kahneman, D. (1983). Extensional versus intuitive reasoning: The conjunction fallacy in probability judgment. Psychological Review, 90, 293-315.
Footnotes
1. Decision making is about whether to intervene and, if so, about what to do. This part of the theory is called Narrative-Based Decision Making. Although it is an important part of the Theory of Narrative Thought, it is not central to the present discussion. Details may be found in Beach, (2010).
2 At a rudimentary level, the differentiation between what-to-expect rules and what-to-do rules is the differentiation between classical conditioning and operant conditioning.
3 Over the course of time, a paradigm may become so refined that its applicability far exceeds the original need for which it was created. Probability theory, for example, is rooted in a narrative need to express uncertainty about the truth of a proposition (a forecast). For example, “It probably will rain.” Hundreds of years of refinement resulted in a self-contained, precise mathematical system in which the concept of probability is so esoteric that it is virtually unrecognizable as the subjective uncertainty about rain that started it. The procedure for applying probability theory, and for doing the required calculations, requires extensive instruction. As a result, although it is commonly used, the word “probability” means different things to the untrained layman and to the statistician.
4 A seventh type of memory, “ …persistence, refers to pathological remembrances; information or events that we cannot forget, even though we wish we could” (p. 183).
5 The questions are “artful” because they are carefully designed to demonstrate mistakes in reasoning. This raises the possibility that what is demonstrated may therefore be more vivid and clear-cut than might be the case in less tailored circumstances.
6 These authors also have used the terms intuitive and extensional for roughly the same differentiation (Tversky & Kahneman, 1983).
7 There is a fourth kind of mistake consisting various heuristics and biases that are not clearly by-products of narrative thinking; e.g., anchoring and adjustment, priming effects, the endowment effect, mental accounts, and others (Kahneman, 2011).
8 Hacking’s (1975) history of probability suggests that in the early days of science, plausibility was in fact what was meant by probability.
|
||